
همانطور که در راهنمای سئو مبتدی اشاره کردیم، موتورهای جستجو دستگاههای پاسخگو هستند. آنها برای کشف، درک و سازماندهی محتوای اینترنت به منظور ارائه نتایج مناسب به سؤالاتی که جستجوگرها از آنها درخواست میکنند، ایجاد شدهاند.
برای نشان دادن نتایج جستجو، ابتدا باید محتوای شما برای موتورهای جستجو قابل مشاهده باشد. احتمالاً مهمترین قطعه معمای SEO است. در واقع اگر سایت شما یافت نشود، به هیچ وجه امکان حضور در SERPs (صفحه نتایج موتورهای جستجو) وجود ندارد.
موتورهای جستجو چگونه کار می کنند؟
موتورهای جستجو سه عملکرد اصلی دارند:
Crawl: هرجا که محتوا روی اینترنت باشد، می روند و لینک ها را بررسی میکنند.
Index: مطالب موجود در طی فرآیند crawl را ذخیره و سازماندهی میکنند. هنگامی که یک صفحه ایندکس شود، شانس دارد که در نتایج جستوجو نشان داده شود.
Rank: بر اساس فاکتورهای بسیاری برای یک کوئری سرچ شده، سایتها را رتبهبندی میکند.
عنکبوت یا خزنده های موتور جستجو چی هستند؟
خزیدن فرایند پیدا کردن است که طی آن موتورهای جستجو تیمی از رباتها (معروف به خزنده یا عنکبوت) را برای یافتن مطالب جدید و به روز شده ارسال میکنند. محتوا میتواند متفاوت باشد – میتواند یک صفحه وب، یک تصویر، یک فیلم، یک PDF و … باشد. اما صرف نظر از قالب، محتوای توسط لینکها (پیوندها) کشف میشود.
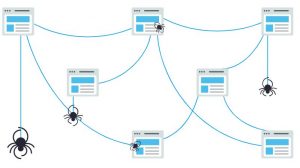
Googlebot با چند صفحه وب شروع به کار میکند، و سپس پیوندها را در این صفحههای وب دنبال میکند تا URLهای جدید پیدا کند. با پیدا کردن مسیرها روی یک صفحه، خزنده یا عنکبوت قادر است محتوای جدیدی پیدا کند و آن را به فهرست خود به نام Caffeine (پایگاهداده گستردهای از URLهای کشف شده) اضافه کند. بعداً وقتی جستجوگر در جستجوی اطلاعاتی باشد که محتوای مناسب و جواب آن سوال در آن URL باشد بازیابی میشود.
فهرست یا ایندکس موتور جستجو چیست؟
موتورهای جستجو اطلاعاتی را که در یک فهرست (همان ایندکس است) دارند پیدا میکنند، و پایگاهداده عظیمی از تمام مطالبی را که کشف کردهاند پردازش و ذخیره میکنند تا به اندازه کافی مناسب برای پاسخگویی به سوالات کاربران باشند.
رتبه بندی موتور جستجو
هنگامی که شخصی یک جستجو را انجام میدهد، موتورهای جستجو فهرست خود را برای آن سوال بررسی میکنند تا بهترین جوابها را به ترتیب اهمیت و پاسخگو بودن لیست کنند.
این ترتیب نتایج جستجو بر اساس اهمیت، به عنوان رتبهبندی شناخته میشود. به طور کلی، میتوانید فرض کنید هرچه وبسایت رتبه بالاتری داشته باشد، موتور جستجو معتقد است که سایت پاسخ خوبی برای این پرسوجو یا کوئری باشد.
میتوان خزندههای موتور جستجو را از بخشی یا تمام سایت شما مسدود کرد یا به موتورهای جستجو دستور داد که از ذخیره صفحات خاصی در فهرست آنها جلوگیری کنند.
در حالی که میتوانید دلایلی برای انجام این کار داشته باشد، اگر میخواهید محتوای شما توسط جستجوگرها پیدا شود، ابتدا باید اطمینان حاصل کنید که برای خزندگان و رباتهای گوگل قابل دسترسی است و قابل ایندکس شدن است. در غیر این صورت، نامرئی هستند.
—————————————–
در سئو، همه موتورهای جستجو برابر نیستند
بسیاری از مبتدیان از اهمیت نسبی موتورهای جستجوگر خاص تعجب می کنند. بیشتر مردم میدانند که گوگل بیشترین سهم بازار را دارد، اما بهینهسازی بینگ، یاهو و دیگران چقدر مهم است؟ حقیقت این است که علیرغم وجود بیش از 30 موتور جستجوگر بزرگ وب، انجمن SEO تنها واقعاً به Google توجه میکند. چرا؟
پاسخ کوتاه این است که گوگل جایی است که اکثریت قریب به اتفاق افراد وب را جستجو میکنند. اگر از Google تصاویر، Google Maps و YouTube (یک ویژگی Google) استفاده کنیم، بیش از 90٪ جستجوهای وب در Google اتفاق میافتد – تقریباً 20 برابر Bing و Yahoo.
خزنده: آیا موتورهای جستجو میتوانند صفحات شما را پیدا کنند؟
همانطور که تازه آموختهاید، اطمینان از اینکه سایت شما در دسترس خزندهها و قابل ایندکس شدن باشد، پیش نیاز برای نمایش در SERPها است.
اگر یک وبمستر یا صاحب یک وب سایت هستید، شاید با دیدن تعداد بسیاری از صفحات شما در این فهرست شروع به کار کنید. این بینش بسیار خوبی در مورد اینکه آیا Google در حال خزیدن و یافتن تمام صفحاتی است که شما میخواهید رتبه بگیرند.
یکی از راههای بررسی صفحات فهرستبندی شده شما “site:yourdomain.com” ، یک اپراتور جستجوی پیشرفته است. به Google بروید و “site:alibaba.ir” را در نوار جستجو تایپ کنید. با این کار نتایج گوگل از صفحات سایت را که ایندکس شده اند را می بینید.
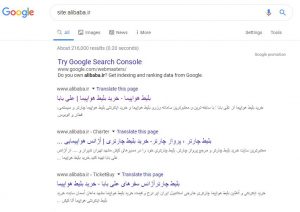
تعداد نتایج نمایش داده شده در گوگل دقیق نیست، اما این ایده را به شما میدهد که صفحات سایت شما ایندکس میشوند و الان چطوری در نتایج جستجو نشان میدهند.
برای نتایج دقیق تر، گزارش Index Coverage را در کنسول جستجوی Google بررسی کنید. اگر در حال حاضر آن را ندارید، میتوانید یک Google Search Console account بسازید. با استفاده از این ابزار، میتوانید نقشه سایت برای سایت خود ست کنید و چک کنید که تعداد صفحات ارائه شده، به فهرست Google اضافه شده است یا خیر.
اگر در هیچ کجای نتایج جستجو نیستید، ممکن است به خاطر دلایل زیر باشد:
- سایت شما کاملاً جدید است و هنوز ربات گوگل آن را ندیده است.
- سایت شما با هیچ وبسایت دیگری لینک ندارد.
- منو و لینکسازی داخلی سایت شما باعث میشود که یک ربات نتواند صفحات را به راحتی پیدا کند.
- سایت شما کدی دارد که موتورهای جستجو را مسدود کرده است.
- سایت شما توسط Google به دلیل تاکتیکهای کلاه سیاه پنالتی و جریمه شده است.
به موتورهای جستجو بگویید چگونه سایت خود را خز کنند.
اگر از کنسول جستجوی Google یا اپراتور جستجوی پیشرفته “site: domain.com” استفاده کردهاید و متوجه شدهاید که برخی از صفحات مهم شما از ایندکس حذف نشدهاند یا برخی از صفحات بیاهمیت شما به طور اشتباه به ایندکس شدهاند، نکاتی برای بهینهسازی این وضعیت وجود دارد.
با اجرایی کردن آنهای به Googlebot کمک میکنید که بهتر محتوای وبسایت شما را کرال کند. راستی کرال باجت، مشکلات کرال شدن صفحات جدید و اینکه بررسی آپدیتهای شما توسط رباتهای گوگل را جدی بگیرید.
اکثر مردم فکر میکنند که Google میتواند صفحات مهم را خودش پیدا کند. این موارد ممکن است شامل مواردی مانند URLهای قدیمی باشد که دارای محتوای کم، لینکهای تکراری (مانند پارامترهای مرتبسازی و فیلتر برای تجارت الکترونیکی)، صفحات تبلیغی ویژه، صفحات مرحله بندی یا تست و … هستند.
برای دسترسی یا عدم دسترسی Googlebot به صفحات و بخشهای خاص سایت خود، از robots.txt استفاده کنید.
Robots.txt
فایل های Robots.txt در فهرست اصلی وب سایت ها قرار دارند (مانند yourdomain.com/robots.txt) و نشان می دهد کدام قسمت از موتورهای جستجوگر سایت شما باید و نباید کرال شوند، همچنین سرعتی که سایت شما را کرال می کند.
چگونه Googlebot با پرونده robots.txt رفتار می کند.
- اگر Googlebot نتواند یک فایل robots.txt برای یک سایت پیدا کند، خودش می رود برای کرال کردن سایت.
- اگر Googlebot یک فایل robots.txt را برای یک سایت پیدا کند، معمولاً پیشنهادات را قبول می کند.
- اگر Googlebot هنگام تلاش برای دسترسی به فایل robots.txt یک سایت با خطایی روبهرو شود و نتواند تعیین کند که این فایل وجود دارد یا خیر، نمی تواند سایت را کرال کند.
بودجه کرال سایت را بهینه سازی کنید!
بودجه کرال میانگین تعداد URLهایی است که Googlebot قبل از خروج از سایت شما کرال کرده است، بنابراین بهینه سازی بودجه خزیدن یعنی اطمینان حاصل کنید که Googlebot وقت زیادی را برای خزیدن از طریق صفحات بیاهمیت خود تلف نمیکند، و خطر دیده نشدن و کرال نشدن صفحات مهم شما است.
بودجه کرال در سایتهای بسیار بزرگ با دهها هزار آدرس اینترنتی مهم است، اما اصلا بد نیست که دسترسی خزندگان به محتوا را که به آنها اهمیت نمیدهید، مسدود کنید.
فقط اطمینان حاصل کنید که دسترسی یک خزنده به صفحاتی که در آنها کلی لینک و دسترسی به صفحات دیگر است مسدود نکنید. اگر دسترسی Googlebot به یک صفحه مسدود شده باشد، بعد از آن صفحه را کرال نمیکند.
همه رباتهای وب از robots.txt پیروی نمیکنند. افراد با نیت بد (به عنوان مثال، اسکرپرها آدرس ایمیل) رباتهایی را ایجاد میکنند که از این پروتکل پیروی نمیکنند. در حقیقت، برخی بازیگران بد از پروندههای robots.txt استفاده میکنند تا بفهمند محتوای خصوصی خود را در کجا قرار دادهاید.
اگرچه به نظر میرسد مسدود کردن خزندهها از صفحات خصوصی مانند ورود به سایت و صفحههای مدیریت منطقی به نظر برسد، زیرا در این فهرست قرار نمیگیرند، قرار دادن محل آن URLها در یک فایل قابل دسترسی عمومی robots.txt همچنین به معنای این است که افراد با قصد مخرب راحت تر میتوانید آنها را پیدا کنند، بهتر است این صفحات را NoIndex کنید.
تعریف پارامترهای URL در GSC
برخی از سایتها (رایجترینها تجارت الکترونیکیها هستند) با اضافه کردن پارامترهای خاصی در URLها، محتوای مشابه را در چندین URL مختلف در دسترس قرار میدهند.
اگر به صورت آنلاین خرید کرده باشید متوجه شدید در یک وبسایت باید محصولی که سرچ کردهاید را دقیق تر و دقیقتر کنید، احتمالاً جستجوی خود را از طریق فیلترها کاهش دادهاید.
به عنوان مثال، شما میتوانید “کفش” را در آمازون جستجو کنید و سپس جستجوی خود را با توجه به اندازه، رنگ و سبک اصلاح کنید. هر بار که پالایش میکنید، URL کمی تغییر میکند:
https://www.example.com/products/women/dresses/green.htmhttps://www.example.com/products/women?category=dresses&color=greenhttps://example.com/shopindex.php?product_id=32&highlight=green+dress&cat_id=1&sessionid=123$affid=43
چگونه گوگل میداند کدام نسخه از URL را برای کاربرانش ارائه کند؟ گوگل به خوبی میداند URL اصلی را به تنهایی تشخیص دهد، اما میتوانید از فیچرهای پارامترهای URL در کنسول جستجوی Google استفاده کنید تا دقیقاً به Google بگویید که چگونه میخواهید آنها را با صفحات خود متمایز کنید.
اگر از این ویژگی برای گفتن Googlebot به “کرال این URL بدون پارامتر ____ ” استفاده میکنید، در اصل میخواهید این محتوا را از Googlebot مخفی کنید، که میتواند منجر به حذف آن صفحات از نتایج جستجو شود. اگر این پارامترها صفحات تکراری ایجاد کنند، همان چیزی است که شما میخواهید، اما اگر میخواهید این صفحات ایندکس شوند، اصلا مناسب نیستند.
آیا رباتهای خزنده میتوانند محتوای مهم شما را پیدا کنند؟
الان که نکاتی در مورد اینکه چطوری جلوی ربات های گوگل برای کرال نکردن صفحات بی ارزش را می دانید، بیایید در مورد بهینه سازی هایی که می تواند به Googlebot کمک کند تا صفحات مهم شما را پیدا کند، بپردازیم.
بعضی مواقع موتور جستجو می تواند با خزیدن قسمت هایی از سایت شما را پیدا کند، اما صفحات یا بخش های دیگر ممکن است به دلایلی از دید ربات پنهان بمانند. این مهم است که مطمئن شوید موتورهای جستجو قادر به پیدا کردن تمام مطالب مورد نظر و مهم شما هستند و نه فقط صفحه اصلی شما.
از خود این سوال را بپرسید: آیا ربات می تواند بین صفحات شما بخزد و همه ی آنها را مشاهده کند؟
آیا محتوای شما در پشت فرمهای ورود مخفی شده است؟
اگر کاربران برای دسترسی به محتوای شما باید عملیات ورود انجام دهند، فرمی را پر کنند یا در یک نظرسنجی شرکت کنند، در اینصورت موتورهای جستجو قادر به دیدن آن صفحات نخواهند بود. قطعا رباتهای خزنده برای ورود به یک صفحه نمیتوانند فرآیند ورود را طی کنند!
آیا به فرمهای جستجو دل خوش کردهاید؟
رباتها نمیتوانند از فرمهای جستجو استفاده کنند. برخی از افراد معتقدند اگر یک باکس جستجو در سایت خود قرار دهند، در این صورت موتورهای جستجو قادر خواهند بود تا هرچیز را که کاربران جستجو میکنند در وبسایت آنها پیدا کنند.
آیا متن به وسیله یک محتوای غیرمتنی پنهان شده است؟
محتواهای غیرمتنی (مانند عکس، ویدئو و GIF) نباید برای نمایش متنی به کار بروند که شما انتظار دارید ایندکس شود. هرچند موتورهای جستجو با گذر زمان در تشخیص عکسها پیشرفت بسیاری کردهاند، اما هنوز هیچ تضمینی وجود ندارد که بتوانند متن موجود در عکس را شناسایی کنند.
همیشه بهترین راه برای اطمینان از قابل دسترسی بودن محتوای متنی، قرار دادن آن در داخل تگهای HTML و در محل مناسب خود است.
آیا موتورهای جستجو میتوانند سایت شما را پیمایش کنند؟
همانگونه که یک ربات خزنده برای برای دسترسی به وبسایت شما از لینکهای موجود در سایر وبسایتها استفاده میکند، برای دسترسی به تمام صفحات سایت نیز نیازمند یک مسیر از لینکهایی است که آن را در طول صفحات راهنمایی کند. اگر شما در وبسایتتان صفحهای دارید که از هیچ صفحهی دیگری لینک نداشته باشد، دقیقا مانند این خواهد بود که یا صفحهای وجود ندارد یا نامرئی است!
بسیاری از سایتها در ساختار پیمایش سایت خود دچار اشتباهات اساسی میشوند که منجر به عدم دسترسی موتورهای جستجو و در نتیجه جا افتادن از نتایج جستجو میشود.
اشتباهات رایجی که در ساختار پیمایش سایت رخ میدهد و مانع از بازدید تمامی صفحات سایت توسط رباتهای جستجوکننده میشود:
- تفاوت مسیر پیمایش موجود در نسخه موبایل سایت و نسخه اصلی آن
- هر گونه المانی از مسیر پیمایش که با زبانی غیر از زبان HTML برنامهنویسی شده باشد، مانند منوهایی که با JavaScript برنامهنویسی شده باشند. هرچند گوگل در کرال کردن و فهمیدن زبان JavaScript بسیار عالی عمل میکند اما با این حال، این کار یک فرآیند عالی و بدون نقص نیست. بهترین روش برای اطمینان از پیدا شدن، بررسی و ایندکس شدن یک محتوا توسط گوگل این است که توسط HTML برنامهنویسی شده باشد.
- شخصیسازی یا نمایش یک مسیر پیمایش خاص برای دستهای از کاربران و تفاوت آن با مسیر پیمایش معمولی، میتواند باعث بروز Cloaking برای موتورهای جستجو شود.
- هیچگاه لینک دادن به صفحه اولیه وبسایت خود را در طول مسیر پیمایش فراموش نکنید. توجه داشته باشید که لینکها مسیری هستند که رباتها را به صفحات جدید هدایت میکنند و رباتها نیز از صفحه اصلی وبسایت شما شروع به کرال کردن میکنند. بنابراین اگر از صفحه اصلی به مسیر پیمایش دسترسی وجود نداشته باشد، همهچیز بر باد خواهد رفت.
اینها همه دلایلی هستند که بیانگر اهمیت مسیر پیمایش واضح و ساختار مناسب پوشه URL برای وبسایت هستند.
آیا معماری اطلاعات سایت شما واضح و منظم است؟
معماری اطلاعات فرآیندی است که در طی آن محتوای موجود در وبسایت دستهبندی و نامگذاری میشود تا قابلیت دسترسی و کارایی آن برای کاربران بهبود پیدا کند.
بهترین حالت معماری اطلاعات حالتی است که Intuitive (کلمهای با معنای تقریبی قابلیت درک سریع) باشد، یعنی نیاز نباشد که کاربران برای گردش در سایت و دسترسی به یک مطلب تفکر زیادی انجام دهند که باید از کدام مسیر بروند بلکه سریعا بتوانند به مقصود خود برسند.
آیا از Sitemap ها (نقشه سایت) استفاده میکنید؟
تعریف نقشه سایت از معنای آن مشخص است: لیستی از URLهای سایت شما که رباتهای خزنده میتوانند از آن برای بازدید صفحات و ایندکس کردن آنها استفاده کنند.
یکی از روشهایی که میتوان مطمئن شد گوگل به صفحات مهم وبسایت شما دسترسی پیدا خوهد کرد، ساخت یک فایل نقشه سایت بر اساس استانداردهای گوگل و ارسال آن به Google Search Console است.
هرچند این فایل جای یک مسیر پیمایش خوب برای سایت را نخواهد گرفت، اما قطعا به رباتهای جستجو کنند کمک خواهد کرد تا به تمام صفحات مهم وبسایت شما دسترسی پیدا کنند.
از قرار دادن URL هایی که توسط robots.txt بلاک شده یا صفحات کپی به جای صفحات اصلی در نقشه سایت خودداری کنید.
اگر سایت شما هیچ لینکی از دیگر سایتها دریافت نکرده و ایندکس نشده است، با ارسال نقشه سایت در سرچ کنسول میتواند ایندکس شود. البته در این رابطه هیچ تضمینی وجود ندارد ولی خوب ارزش امتحان کردن را خواهد داشت!
برای سفارش طراحی سایت و خدمات سئو سایت جواد یاسمی به صفحه طراحی سایت مشهد بروید و نمونه کارهای طراحی سایت را مشاهده کنید.
آیا ممکن است رباتهای خزنده برای دسترسی به URLهای شما با خطا مواجه شوند؟
در فرآیند کرال کردن URL های وبسایت، رباتهای خزنده ممکن است با خطا مواجه شوند. برای اطلاع از این خطاها شما میتوانید به بخش “Crawl Errors” در سرچ کنسول مراجعه کنید. در این بخش گزارشی به شما ارائه خواهد شد که URL هایی که ممکن است با خطا مواجه شوند را نشان خواهد داد. این خطاها شامل خطاهای سرور و خطاهای عدم وجود (not found) میشوند. فایلهای لاگ سرور نیز میتوانند این اطلاعات را نمایش دهند و علاوه بر آن شامل اطلاعات باارزش دیگری مانند فرکانس کرال کردن (تعداد دفعاتی که یک وبسایت در یک باز زمانی کرال میشود) نیز میشوند. اما به دلیل اینکه دسترسی و تشریح فایلهای لاگ سرور یک تاکتیک پیشرفته است، در این راهنمای مبتدی به آن نخواهیم پرداخت.
قبل از اینکه بتوانید از گزارش خطاهای سرچ کنسول استفاده کنید، نیاز است که با انواع خطاهای موجود در آن آشنا باشید.
خطای کد 4xx : هنگامی رباتهای جستجوکننده به دلیل خطای سمت کاربر نتوانند به محتوای شما دسترسی پیدا کنند.
خطاهای 4xx خطاهای سمت کاربر هستند. به این معنی است که یا URL درخواست شده سینتکس (شیوه و علائم نوشتاری یک زیان برنامهنوسی) ناقص و اشتباهی دارد یا درخواست کاربر قابل برآورده کردن نیست. یکی از شایعتری خطاهای 4xx خطای “404 – not found” است.
این خطاها میتوانند به دلایل مختلفی از جمله غلط بودن آدرس URL، پاک شدن صفحه یا تغییر مسیر اشتباه اتفاق بیفتند. هنگامی که موتورهای جستجو به 404 برمیخورند، به این معنی است نمیتوانند به URL موردنظر دسترسی پیدا کنند. هنگامی هم که کاربران به 404 برمیخورند، ناامید شده و وبسایت را ترک میکنند.
خطای کد 5xx: هنگامی که رباتهای جستجوکننده به دلیل خطای سرور نتوانند به محتوای شما دسترسی پیدا کنند.
خطاهای 5xx خطاهای سمت سرور هستند. به این معنی است که سروری که وبسایت بر روی آن بارگذاری شده است، در اجرای درخواست کاربران یا موتورهای جستجو برای دسترسی به سایت با مشکل مواجه شده است.
در گزارش سرچ کنسول، بخشی وجود دارد که به این نوع خطاها اختصاص داده شده است. این خطا معمولا هنگامی رخ میدهد که درخواست منقضی شده باشد و گوگلبات درخواست را رها کند. برای اطلاعات بیشتر در رابطه با رفع مشکلات سرور میتوانید از مستندات گوگل که در این رابطه نوشته شدهاند استفاده کنید.
خوشبخانه راهحلی برای اعلام جابهجای صفحه وب به کاربران و موتورهای جستجو وجود دارد، و آن تغییر مسیر کد 301 (تغییر مسیر دائمی) است.
صفحات 404 وبسایت خود را بهبود ببخشید.
شما میتوانید با اضافه کردن لینک صفحات مهم وبسایت، یک المان جستجو در سایت و حتی اطلاعات تماس خود به صفحه 404 آن را بهبود ببخشید. اینکار احتمال ترک بازدیدکنندگان پس از برخورد به صفحه 404 را کاش میدهد.
برای اینکه به کاربران و موتورهای جستجو اعلام کنید صفحهای که در یک URL وجود داشته به آدرسی جدید جابهجا شده است و آنها را به آدرس جدید هدایت کنید، نیازمند یک پل ارتباطی هستید. آن پل ارتباطی “301 Redirect” است.
| استفاده از 301 | عدم استفاده از 301 | |
| ارزش و اعتبار لینکها | انتقال تمام ارزش و اعتبار لینکها از صفحه قدیمی به آدرس URL جدید | بدون استفاده از 301 قدرت دامنه که در URL قبلی وجود داشت به نسخه جدید منتقل نخواهد شد. |
| ایندکس کردن | کمک به گوگل در یافتن و ایندکس کردن نسخه جدید صفحه | حضور خطاهای 404 در وبسایت که نهتنها به عملکرد شما در جستجو آسیب خواهد رساند، بلکه باعث خارج شدن صفحه از ایندکس گوگل و از دست رفتن بخشی از ترافیک وبسایت نیز خواهد شد. |
| تجربه کاربری | به کاربران تضمین میدهد که صفحه موردنظر خود را پیدا خواهند کرد. | کاربران با کلیک بر روی لینکهای بیمصرف به صفحات خطا راهنمایی خواهند شد، صفحه موردنظر خود را پیدا نخواهند کرد و تاثیری منفی بر روی تجربه کاربری وبسایت رخ خواهد داد. |
کد 301 به این معنی است که صفحه موردنظر به صورت دائمی جابهجا شده و به یک مکان جدید انتقال پیدا کرده است، با استفاده از این روش کاربر با استفاده از URL قدیمی میتواند مستقیما به صفحه جدید راهنمایی شود و دیگر با صفحه خطا یا هر صفحه نامربوط دیگری مواجه نخواهد شد.
صفحهای که دیگر محتوای مورد نظر در آن وجود ندارد. اگر صفحهای برای یک جستار خاص به رتبه بالا دست یافته باشد و شما با استفاده از کد 301 آن را به یک URL با محتوای متفاوت انتقال دهید، ممکن است جایگاه خود را از دست دهد. دلیل آن نیز این است که محتوایی که آن صفحه را به جستار مربوط میکرد دیگر در آنجا وجود ندارد. کد 301 ابزار قدرتمندی است، لذا با احتیاط از آن استفاده کنید.
برای جابهجایی یک صفحه شما همچنین میتوانید از کد 302 استفاده نمایید. استفاده از این کد تنها در موارد ضروری مناسب است. مواردی که در آن نگران انتقال ارزش لینکها نباشیم.
کد 302 مانند یک مسیر انحرافی و موقت است که با استفاده از آن میتوان به طور موقت ترافیک را به یک مسیر مشخص هدایت کرد، اما نه به صورت دائمی و تنها برای موارد ضروری قابل استفاده است.
مراقب زنجیره تغییر مسیرها باشید.
برای رباتهای گوگل مشکل خواهد بود که برای دسترسی به صفحه شما مجبور باشند از چند تغییر مسیر عبور کنند. گوگل این اتفاق را زنجیره تغییر مسیر مینامد و توصیه میکند که آن را تا حد امکان کاهش دهید، برای مثال اگر شما example.com/1 را به example.com/2 انتقال داده و سپس دوباره تصمیم بگیرید که example.com/2 را به example.com/3 انتقال دهید، بهتر است که واسطه میانی را حذف کرده و example.com/1 را مستقیما به example.com/3 انتقال دهید.
هنگامی که از بهینه بودن سایت خود رباتهای خزنده مطمئن شدید، قدم بعدی کسب اطمینان از قرارگیری در ایندکس موتور جستجو خواهد بود.
ایندکس کردن: موتورهای جستجو چگونه صفحات شما را بررسی و ذخیره میکنند؟
اطمینان از دسترسی و کرال شدن صفحات وب توسط موتورهای جستجو حتما منجر به ذخیره شدن این صفحات در فهرست آنها نخواهد شد. در بخش قبلی ما در رابطه با این مساله صحبت کردیم که چگونه موتورهای جستجو صفحات شما را پیدا میکنند.
فهرست یا ایندکس جایی است که صفحات یافت شده ذخیره میشوند. هنگامی که یک ربات جستجو کننده صفحهای را پیدا میکند، موتور جستجو این صفحه را همانند مرورگر رندر میکند. در ادامه موتور جستجو محتوای صفحه را آنالیز کرده، دستهبندی میکند و تمام اطلاعات را در فهرست خود ذخیره میکند.
در ادامه به توضیح این مساله میپردازیم که فرآیند ایندکس کردن چگونه اتفاق میافتد و چگونه میتوانید مطمئن شوید که محتوای وبسایت داخل این بانک اطلاعاتی مهم (فهرست گوگل) قرار خواهد گرفت.
آیا من میتوانم آنگونه که رباتها صفحه وبسایت من را مشاهده میکنند، مشاهده کنم؟
جواب این سوال مثبت است. نسخه ذخیره شده (cached) صفحه وبسایت دقیقا همانگونه است که آخرین بار ربات گوگل آن صفحه را کرال کرده.
گوگل صفحات وب را در بازههای زمانی منظمی کرال و ذخیره میکند. این بازههای زمانی برای سایتهای بسیار معروف و شناخته شده ( مانند https://www.nytimes.com) کوتاه و سریع و برای سایتهای کمتر شناخته شده بلند و تک و توک خواهد بود.
شما میتوانید نسخه ذخیره شده صفحه خود را به صورت زیر و با انتخاب گزینه Cached در صفحه نتایج جستجو مشاهده نمایید.
شما همچنین میتوانید نسخه متنی وبسایت خود را مشاهده کنید تا از کرال شدن و ذخیره محتوای مهم خود به طور موثر اطلاع پیدا کنید.
آیا ممکن است صفحات از ایندکس حذف شوند؟
جواب مثبت است. برخی از دلایل اصلی که منجر به این اتفاق میشود را میتوان به صورت زیر برشمرد:
- هنگامی که URL با خطای 4xx “not found” یا خطای 5xx مواجه شود. این وضعیت ممکن است اتفاقی ( صفحه حذف شده اما هنوز تغییر مسیر 301 بر روی آن اجرا نشده است.) یا عمدی باشد ( صفحه حذف شده و کد 404 اعلام شده به این دلیل که از ایندکس حذف شود).
- آدرس URL شامل متا تگ nonindex باشد. این تگ میتواند از طرف صاحبان سایت برای جلوگیری از ایندکس شدن صفحه توسط موتورهای جستجو اضافه شود.
- آدرس URL به دلیل تخطی از استانداردهای مدریت سایت موتورهای جستجو جریمه شده و از ایندکس حذف شود.
- به دلیل نیاز به پسورد قبل از دسترسی به سایت، آدرس URL توسط رباتهای جستجو کننده بلاک شود.
اگر فکر میکنید که یکی از صفحات وبسایت شما که در ایندکس گوگل بود و دیگر در نتایج جستجو نمایش داده نمیشود، میتوانید با استفاده از ابزار URL Inspection از وضعیت آن مطل شوید. یا میتوانید با استفاده از Fetch as Google درخواست ورود به ایندکس برای یک URL خاص را بدهید.
به موتورهای جستجو بگویید چگونه وبسایت شما را ایندکس کنند.
Robots meta directives (دستورات متا برای رباتها)
دستورات متا (یا meta tags) دستوراتی هستند که با استفاده از آنها میتوانید نحوه رفتار موتورهای جستجو در سایت خود را مشخص کنید.
شما میتوانید برای رباتهای جستجو کننده دستوراتی صادر کنید، برای مثال، میتوانید به رباتها بگویید که یک صفحه را در نتایج جستجو ایندکس نکنند یا برای هیچکدام از لینکهای داهلی، ارزش و اعتباری قائل نشوند.
این دستورات میتوانند به دو صورت اجرا شوند. یا با استفاده از Robots Meta Tags که در بخشکد HTML صفحه قرار میگیرند (رایجترین روش مورد استفاده است) یا با استفاده از X-Robots-Tag که در بخش HTTP آدرس سایت استفاده میشوند.
Robots meta tag
این عبارات در داخل بخشکد HTML استفاده میشوند و میتوانند از دسترسی همه یا برخی از موتورهای جستجو به محتوای شما جلوگیری کنند. در ادامه پرکاربردترینِ این دستورات به همراه موارد استفاده آنها آورده شده است.
Index/noindex: این دستور به موتورهای جستجو میفهماند که صفحه موردنظر باید کرال شده و ایندکس شود یا خیر. اگر شما از دستور noindex استفاده کنید، رباتهای جستجوکننده آن صفحه را از نتایج جستجو مستثنی خواهند کرد.
به صورت پیشفرض موتورهای جستجو فرض میکنند که تمام صفحات قابلیت ایندکس شدن دارند پس استفاده از دستور index عملا غیرضروری بهنظر میرسد.
- شما میتوانید از این دستور برای جلوگیری از ایندکس شدن صفحات بیارزش خود توسط گوگل استفاده کنید. (صفحاتی مانند صفحات پروفایل که توسط کاربران ساخته شده است). توجه کنید که این صفحات تنها برای موتورهای جستجو غیرقابل دسترس میشوند اما کاربران هنوز میتوانند به آنها دسترسی پیدا کنند.
Follow/nofollow: این دستور به موتورهای جستجو اعلام میکند که لینکهای موجود در یک صفحه باید دنبال شوند یا خیر. دنبال شدن لینکها باعث میشود که رباتها بتوانند با استفاده از آن لینکها به صفحات مختلف دسترسی پیدا کرده و براساس آن لینک قدرت URL را افزایش دهند. با استفاده از دستور nofollow میتوانید از این کار جلوگیری کنید. به صورت پیش فرض همه صفحات در حالت follow قرار دارند.
- nofollow معمولا به همراه noindex استفاده میشود و هم از ایندکس شدن صفحه و هم از دنبال شدن لینکهای موجود در صفحه توسط کرال کننده جلوگیری به عمل میآورد.
Noarchive: هدف از این دستور جلوگیری از ذخیره کردن نسخه کپی سایت شما توسط موتورهای جستجو است. به صورت پیشفرض موتورهای جستجو یک نسخه کپی از تمام صفحاتی که ایندکس کردهاند ذخیره میکنند. این نسخه از طریق لینک cached موجود در نتایج جستجو برای کاربران قابل دسترسی خواهد بود.
- اگر شما یک سایت فروشگاهی راهاندازی کنید و قیمتها به صورت متناوب تغییر کند، استفاده از این دستور باعث میشود که کاربران قیمتهای قدیمی را مشاهده نکرده و قیمتهای جدید را دریافت کنند.
در اینجا یک نمونه مثال از دستورات noindex و nofollow آورده شده است:
در این مثال، تمام موتورهای جستجو از ایندکس کردن صفحه و دنبالکردن لینکهای موجود در آن منع شدهاند. اگر قصد داشته باشید که رباتهای خاصی را، مانند رباتهای گوگل و بینگ، منع کنید باید از چند تگ مختلف استفاده کنید.
دستورات متا تنها بر روی فرآیند ایندکس کردن تاثیر میگذارند، نه فرآیند کرال کردن.
رباتهای گوگل برای اینکه دستورات متا را مشاهده و آن را اجرا کنند نیاز دارند که صفحه شما را کرال کنند. بنابراین اگر شما میخواهید که از دسترسی رباتهای کرال کننده به برخی از صفحات خود جلوگیری کنید، با استفاده از دستورات متا نمیتوانید این کار را انجام دهید.
X-Robots-Tag
تگهای x-robots در عنوان HTTP آدرس URL شما استفاده میشوند. این دستورات انعطافپذیری و کارایی بیشتر نسبت به متا تگها دارند. دلیل آن هم این است که شما با عبارات ساده و معمولی میتوانید دسترسی موتورهای جستجو را قطع کنید، فایلهای غیر HTML را بلاک کنید و برای تمام سایت noindex اعمال کنید.
برای مثال میتوانید دسترسی به تمام پوشهها را منع کنید:
یا برخی انواع فایلها مانند PDF:
برای اطلاعات بیشتر از این دستوران میتوانید عبارت Google’s Robots Meta Tag Specifications را جستجو کرده و به منابع اصلی و مفید گوگل دسترسی پیدا کنید.
نکتهای در رابطه با وردپرس: در مسیر Dashboard > Settings > Reading مطمئن شوید که Search Engine Visibility تیک نخورده باشد. این ویژگی دسترسی موتورهای جستجو با استفاده از فایل robots.txt به سایت شما را قطع میکند.
داشتن درک درست از روشهای مختلفی که میتوان بر فرایند کرال کردن و ایندکس کردن تاثیر گذاشت، به شما کمک میکند تا از مشکلات رایج خلاص شوید. مشکلاتی که باعث میشوند تا صفحات مهم شما توسط موتورهای جستجو شناسایی نشوند.
رتبهبندی: موتورهای جستحو چگونه URLها را رتبهبندی میکنند.
موتورهای جستجو چگونه مطمئن میشوند که وقتی یک کاربر عبارتی را جستجو میکند، نتایج مفید و مرتبطی به دستش خواهد رسید؟
این فرآیند تحت عنوان ردهبندی یا رتبهبندی شناخته میشود، فرآیندی که در آن نتایج جستجو بر اساس میزان ارتباط با جستار کاربر از اول تا آخر دستهبندی میشوند.
برای ارزیابی ارتباط نتایج با جستار کاربر، موتورهای جستجو از الگوریتمها استفاده میکنند. الگوریتمها فرآیند یا فرمولهایی هستند که اطلاعات ذخیره شده را بازیابی کرده و آنها را براساس یک معیار خاص دستهبندی و مرتب میکنند.
این الگوریتم در طول سالیانی که موتورهای جستجو شروع به کار کردند تغییرات بسیاری کردهاند تا همواره بهترین موارد را به عنوان نتایج جستجو ارائه دهند.
برای مثل گوگل هر ساله الگوریتمهای خود را آپدیت میکند. برخی از این آپدیتها شامل تغییرات جزئی میشوند درحالی که برخی دیگر اساسی و بنیادی هستند و برای برطرف کردن یک مشکل خاص انجام شدهاند.
برای مثال آپدیت پنگوئن برطرف کردن مشکل لینک اسپم را هدف قرار داده است. اگر اطلاعات بیشتری در رابطه با این آپدیتها نیاز دارید، میتوانید با جستجو در اینترنت تاریخچه و دلیل آنها را سریعا پیدا کنید.
اما آیا تا به حال این سوال را از خود کرده اید که چرا الگوریتمها سریعا تغییر میکنند؟ آیا گوگل میخواهد همیشه ما را مشغول ایجاد تغییرات و وفق دادن با خودش نگه دارد؟
درحالی که همیشه جزییات و اهداف اقدامات گوگل از طرف خودشان اعلام نمیشود، اما در این یک مورد برای ما واضح است که هدف تغییرات و آپدیتهای مکرر، بهبود کیفیت جستجو برای کاربران است.
به همین دلیل است که گوگل همیشه در جواب سوالاتی که در رابطه با آپدیت الگوریتمها پرسیده میشود، جواب خود را با این عبارت به پایان میبرد: “ما همیشه به دنبال بهبود کیفیت به وسیله آپدیتها هستیم”.
اگر وبسایت شما پس از ایجاد تغییرات در الگوریتمهای گوگل با مشکل مواجه شود، باید به دو منبع مهم مراجعه کنید تا از دستورالعملها و انتظارات موتورهای جستجو در رابطه با وبسایتها و محتوای آنها اطلاع پیدا کنید و بتوانید وبسایت خود را با آن معیارها مقایسه کرده و بهبود ببخشید.
این دو منبع Google’s Quality Guidelines (شیوهنامههای کیفی گوگل) و Search Quality Rater Guidelines (شیوهنامههای کیفی ردهبندی در جستجو) هستند.
انتظارات موتورهای جستجو چیست؟
موتورهای جستجو همواره یک خواسته داشتند، دارند و خواهند داشت: فراهم کردن پاسخهای مفید برای سوالات جستجوکنندگان به بهترین شکل ممکن. اما اگر مساله این است، پس چرا فرآیند و ترفندهای سئو در زمان حاضر با سالهای گذشته تفاوت بسیاری کرده است؟
این مساله را در قالب یک مثال بررسی میکنیم. فرض کنید شخصی در حال یادگیری یک زبان جدید است.
در ابتدا درک این شخص از زبان بسیار مبتدی است. با گذشت زمان، درک شخص شروع به عمیق شدن میکند و میتواند مفاهیم را بیاموزد.
معانی که پشت کلمات زبان است را فرا میگیرد و میتواند رابطه بین کلمات و عبارات و جملات را درک کند. و درنهایت و با تمرین بسیار مهارت او در فهم زبان به جایی میرسد که میتواند تفاوتهای ظریف و کنایهها را درک کرده و حتی به سوالات مبهم و ناقص هم پاسخ دهد.
هنگامی که موتورهای جستجو به تازگی شروع به یادگیری زبان انسان کرده بودند، به راحتی میشد با استفاده از ترفندها و روشهای سادهای که استانداردهای کیفیتی را نقض میکردند آنها را به بازی گرفت. برای مثال استفاده مکرر و زیاد از کلیدواژهها یکی از ترفندهای افزایش رتبه در نتایج جستجو بود.
اگر شما میخواستید برای یک کلیدواژه خاص مانند “جوکهای خندهدار” به رتبه اول گوگل دست پیدا کنید، فقط کافی بود تا از این کلیدواژه به طور مکرر در متن خود استفاده کنید، آنرا بولد کنید و امیدوار باشید که فرآیند اول شدن شما را سریعتر کند.
این روش تجربه کاربری وحشتناکی را به وجود میآورد و به جای اینکه کاربر را به خندیدن به جوکهای خندهدار وا دارد او را با انبوهی از کلمات آزاردهنده بمباران میکرد و متنی سخت و ناخوانا را به او ارائه میداد. این روش شاید در گذشته جواب میداد اما هرگز چیزی نبوده که موتورهای جستجو انتظار آن را داشتند.
نقش لینکها در سئو
وقتی که در رابطه با لینکها صحبت میکنیم، دو چیز را منظور نظر داریم. لینکهای ورودی یا بکلینکها، لینکهایی هستند که کاربران را از سایر وبسایتها به سایت شما راهنمایی میکنند و لینکهای داخلی، لینکهایی هستند که از یک صفحه به صفحه دیگری در همان سایت داده میشوند.
لینکها از زمانهای خیلی قبل تا الان نقش بسیار مهمی در سئو ایفا میکردند. در همان ابتدا، موتورهای جستجو برای تشخیص اینکه کدام URL از بقیه باارزشتر و با اهمیتتر است نیاز به کمک داشتند تا بتوانند بر این اساس نتایج جستحو را طبقهبندی کنند. تعداد لینکهای وروردی یک سایت معیاری بود که آنها را در این زمینه بسیار کمک میکرد.
بکلینکها در اینترنت کارکردی مشابه با معرفی دهان به دهان در دنیای واقعی دارند. بگذارید با یک مثال توضیح دهیم. میتوانیم کافیشاپ فرضی الف را درنظر بگیریم و نظرات را در رابطه با آن بررسی کنیم:
- اگر نظرات از سمت دیگران باشد، نشانهای بر خوب بودن کیفیت است.
مثال: بسیاری از اهالی شهر میگویند که کافیشاپ الف بهترین قهوه در سرتاسر شهر را دارد. بنابراین این نظرات تایید کننده این موضوع هستند.
- اگر نظرات از سمت خود شخص باشد، جانبدارانه درنظر گرفته میشود و نشانهای بر کیفیت محسوب نخواهد شد.
مثال: فرض کنید صاحب کافیشاپ الف بگوید این کافیشاپ بهترین قهوه شهر را دارد. کمی خودخواهانه است!
- اگر نظرات از سمت منابع بیربط یا کم کیفیت باشد، نه تنها نشانهای بر خوب بودن کیفیت نخواهد بلکه گاهی نیز ممکن است به بدی اسم در کند.
مثال: صاحب کافیشاپ الف به افرادی که تا به حال از آنجا استفاده نکردهاند، پول بدهد تا از کافیشاپ تعریف کنند.
- اگر نظرات و رفرنسهایی وجود نداشته باشد، کیفیت نیز در هالهای از ابهام قرار خواهد داشت.
مثال: اگرچه قهوه کافیشاپ الف بسیار خوب است ولی اگر شما نتوانید فردی را پیدا کنید که نظری در تایید این موضوع داشته باشد نمیتوانید از کیفیت آن اطمینان پیدا کنید.
به همین دلیل بود که PageRank ساخته شد. PageRank یک الگوریتم آنالیز لینک است که توسط گوگل ساخته شده و نام آن از روی اسم یکی از موسسین گوگل، Larry Page، اقتباس شده است.
این الگوریتم اهمیت یک صفحه وب را براساس تعداد و کیفیت لینکهای ورودی آن تخمین میزند. فرض اساسی این الگوریتم نیز بر این مساله استوار است که هرقدر ارتباط، اهمیت و ارزش یک صفحه وب بیشتر باشد لینکهای بیشتری کسب خواهد کرد.
هرقدر که وبسایت شما بتواند بکلینکهای طبیعی از سایتهای پرقدرت و قابل اعتماد کسب کند، شانس شما برای کسب رتبه بالاتر در نتایج جستجو افزایش خواهد یافت.
نقش محتوا در سئو
اگر شما جستجوکنندگان را به سمت محتوای با ارزش و مفیدی راهنمایی نکنید، در آن صورت استفاده از لینک بیهدف خواهد بود. محتوا چیزی وسیعتر از کلمات را پوشش میدهد، محتوا هرچیزی است بتواند به کاربران کمک کند، به پرسش آنها پاسخ دهد یا چیزی را بر اطلاعات آنها بیفزاید.
در نتیجه وقتی از کلمهی محتوا استفاده میکنیم، منظورمان هم محتوای متنی است و هم محتوای ویدئویی و هم محتوای تصویری. اگر موتورهای جستجو ماشینهای پاسخ دهندهای باشند که کاربران برای یافتن پاسخ خود در آنجا به جستجو میپردازند، محتوا وسیلهای خواهد بود که جواب موردنظر را به کاربران انتقال خواهد داد.
هر زمانی که یک کاربر جستجویی انجام دهد، هزاران نتیجه ممکن است وجود داشته باشد که به جستجوی او مربوط باشد. پس موتورهای جستجو چگونه تصمیم میگیرند که کدام یک برای کاربر مفید است و آن را به او نمایش دهند؟
اصلیترین دلیلی که باعث میشود صفحه شما برای یک جستار خاص در نتایج قرار بگیرد این است که محتوای شما با هدف موجود در پشت جستار مطابقت داشته باشد. به عبارت دیگر، آیا عبارتی که توسط کاربر جستجو شده است با کلمات موجود در این محتوا مطابقت دارد؟
آیا میتواند آنچیزی را که کاربران دنبال آن هستند به آنها ارائه کند؟ اگر جواب این سوالات در وبسایت شما مثبت است، پس میتواند بخشی از نتایج جستجو باشد.
به دلیل اهمیت بالای رضایت کاربر و انجام درست وظیفه پاسخ دادن به او، موتورهای جستجو محدودیتهای سختگیرانهای بر روی طولانی بودن محتوا، تعداد کلمات کلیدی موجود در آن و نوع عناوین اعمال نمیکنند. تمام این موارد میتوانند نقش مهمی در عملکرد یک صفحه وب در جستجو داشته باشند، اما تمرکز اصلی بر روی رضایت کاربرانی است که از محتوا استفاده میکنند.
امروزه، با وجود صدها یا هزاران مزیتی که وبسایتهای مختلف برای ردهبندی نتایج دارند، سه مزیت اصلی کماکان جزو اصلیترینها محسوب میشوند: لینکهایی که به وبسایت شما داده شده است (که به عنوان یک مزیت مفید خارجی برای شما عمل میکند)، محتوای صفحه (محتوایی که با کیفیت باشد و بتواند اهداف جستجوی کاربران را ارضا کند) و در آخر RankBrain.
RankBrain چیست؟
RankBrain نامی است که بر روی بخش یادگیری ماشین الگوریتم اصلی گوگل نهادهاند. یادگیری ماشین (machine learning) یک برنامه کامپیوتری است که مانند انسان توانایی یادگیری دارد و با گذشت زمان، هر قدر مشاهدات و داده آموزش داده شده به آن بیشتر میشود پیشبینیهای دقیقتری ارائه خواهد داد. به عبارت دیگر کامپیوتر همیشه در حال یادگیری است و به دلیل این یادگیری مداوم، نتایج جستجو به صورت دائمی تغییر کرده و بهبود مییابند.
برای مثال اگر RankBrain متوجه شود یک URL که در جایگاه پایینتری در نتایج جستجو قرار دارد محتوای بهتری نسبت به URL های موجود در جایگاه بالاتر خود به کاربران ارائه میدهد، نتایج جستجو را تغییر داده و جایگاه صفحه مذکور را در نتایج جستجو ارتقاء خواهد داد.
ما نمیدانیم RankBrain دقیقا از چه چیزی تشکیل شده است، مانند بسیاری دیگر از موارد موتورهای جستجو که چیز زیادی راجع به آنها نمیدانیم. اما از قرار معلوم خود بر و بچههای گوگل هم نمیدانند!
این مساله چه تاثیری بر سئو دارد؟
همانطور که از اقدامات قبلی نیز مشخص است، گوگل قصد دارد باگذشت زمان، تاثیر الگوریتم RankBrain بر ردهبندی نتایج جستجو را افزایش دهد تا بدین وسیله بتواند محتوای مفید و مرتبط را به خوبی شناسایی کند.
به همین دلیل نیاز است که در فرآیند سئو بیش از پیش تمرکز بیشتری بر روی ارضای هدف جستجوی مخاطبان گذاشته شود. فراهم کردن بهترین تجربه کاربری و اطلاعات ممکن برای افرادی که به وبسایت شما وارد میشوند، اولین و بزرگترین قدم در جهت پیشرفت در دنیای RankBrain است.
معیارهای تعاملی: همبستگی، وابستگی، یا هردو؟
یک سوال اساسی وجود دارد. آیا معیارهای تعاملی با جایگاه صفحه در نتایج جستجو همبسته هستند، یعنی اگر صفحهای یک جایگاه عالی در نتایج جستجو داشته باشد، در تعامل با کاربران عالی عمل خواهد کرد یا این رابطه از نوع رابطه وابستگی و علت و معلولی است، یعنی اگر یک صفحه در تعامل با کاربران خوب ظاهر شود جایگاه آن در نتایج جستجو بالا خواهد رفت. کدام مورد درست است؟ در اینجا باید بگوییم که هردو!
هنگامی که صحبت از معیارهای تعاملی میکنیم، منظورمان دادههایی است که نحوه تعامل جستجوکنندگان با وبسایت شما از طریق نتایج جستجو را بیان میکنند. این معیارها موارد زیر را شامل میشوند:
- کلیکها (بازدیدهایی که از نتایج جستجو وارد میشوند.)
- زمان سپری شده بر روی صفحه یا Time on Page (مقدار زمانی که یک بازدیدکننده بر روی وبسایت شما سپری میکند قبل از اینکه آن را ترک نماید.)
- Bounce rate (درصدی از بازدیدهای وبسایت که کاربران تنها یک صفحه را مشاهده کردهاند)
- Pogo-sticking یا بازگشت سریع (هنگامی که یک کاربر بر روی یکی از نتایج ارگانیک جستجو کلیک کرده، وارد صفحه شده اما آن را مناسب نمییابد و بلافاصله به صفحه نتایج جستجو باز میگردد تا مورد دیگری را انتخاب کند.)
بسیاری از تحقیقات نشان میدهد که کسب رتبه بالا در نتایج جستجو و معیارهای تعاملی رابطهای همبسته و متقابل با یکدیگر دارند، اما بحث در مورد رابطه وابستگی آنها نیز هنوز داغ است.
طراحی سایت در مشهد، کسب و کار شما را رونق میدهد. فرقی ندارد شما چه کسب و کاری دارید آنلاین نشدن کسب و کار شما به زودی باعث خواهد شد که کسب و کار شما رو به نابودی برود.
گوگل در این رابطه چه میگوید؟
درحالی که کارمندان و مهندسان گوگل هیچگاه به صورت شفاف از سیگنالهایی نام نمیبرند که به کمک آنها ردهبندی صفحات تعیین میشوند، اما در یک مورد واضح بیان کردهاند که از تعداد کلیکها برای اصلاح نتایج جستجو در برخی جستارهای مشخص استفاده میکنند.
بر اساس گفتههای Udi Manber، رئیس سایق بخش کیفیت جستجو در گوگل، میتوان به این موضوع پی برد:
“ردهبندی به خودی خود از طرف تعداد کلیکها تحت تاثیر قرار میگیرد. برای مثال اگر در یک جستار خاص ما بفهمیم که مورد دوم 80 درصد کلیک داشته و مورد اول تنها 10 درصد، در مییابیم که مورد دوم چیزی است که کاربران بیشتر به دنبال آن هستند و ارتباط قویتری با هدف جستار دارد، پس جایگاه آن را ارتقا خواهیم داد.”
نظر دیگری از سمت مهندس گوگل، Edmond Lau، این مساله را تایید میکند:
“این مساله بسیار واضح است که هر موتور جستجوی درست و حسابیای از تعداد کلیکها به عنوان یک معیار برای تغییر ردهبندی در جهت بهبود کیفت جستجو استفاده کند. مکانیسمهای استفاده از این اطلاعات برای هر موتور جستجو فرق میکند. گوگل نیز برای استفاده از این اطلاعات، روشهای خاص خود را دارد.”
به دلیل اینکه گوگل نیاز دارد کیفیت جستجو را حفظ و ارتقا ببخشد، به نظر میرسد که درنظر گرفتن رابطه همبستگی برای معیارهای تعاملی و ردهبندی جستجو اجتنابناپذیر باشد. اما باید به این مساله نیز توجه کرد که گوگل در برخی از موارد این معیارها را به عنوان سیگنالهایی برای ردهبندی خطاب میکند. دلیل آن نیز این است که این معیارها برای بهبود کیفیت جستجو استفاده میشوند و بالا رفتن جایگاه URLهای مختلف نیز یک نتیجه فرعی از این بهبود کیفیت است. پس میتوان بین آنها نوعی رابطه وابستگی نیز برقرار نمود.
تحقیقات چه چیزی را تایید میکنند؟
تحقیقات بسیاری نشان میدهد که گوگل ترتیب نتایج جستجو را بر اساس میزان تعامل کاربران تعیین میکند.
- آزمایش Rand Fishkin در سال 2014 نشان میدهد یک URL که در رده هفتم نتایج جستجو قرار گرفته بود، پس از حدود 200 کلیک از طرف کاربران مختلف، در صفحه نتایج جستجو به رده اول دست پیدا کرد. نکته جالب توجه این تحقیق در این بود که مشاهده شد بهبود جایگاه رابطهای مستقیم با مکان و محل بازدید کنندگان داشته است.
درحالی که جایگاه این نتیجه در ایلات متحده بهبود یافته بود در صفحات گوگل کانادا، استرالیا و سایر کشور به همان وضعیت قبلی باقی ماند.
- مقایسه Larry Kim که برروی برخی از صفحات وب و زمان سپری شده در آنها، با درنظر گرفتن و نگرفتن تاثیر الگوریتم RankBrain انجام شد، نشان داد که این الگوریتم صفحاتی را که زمان کمتری درآنها سپری شده بود تنزل رتبه میدهد.
- آزمایش Darren Shaw نیز نشان داده که رفتار کاربران و تعامل آنها بر رو جستجوهای مکانی و نتایج نقشه گوگل نیز تاثیر میگذارد.
از آنجایی که به صورت واضح از معیارهای تعاملی کاربران برای اصلاح کیفیت نتایج جستجو استفاده میشود و جایگاه یک صفحه در بین نتایج محصول فرعی این معیارهاست، بهتر است که فرآیند سئو بر اساس دستیابی به بهینهترین حالت معیارهای تعاملی برنامهریزی شود.
توجه کنید که این مساله هدف دستیابی به کیفیت بالا در وبسایت را تغییر نخواهد داد. اما این نکته را نیز باید درنظر گرفت که ارزش شما برای جستجوکنندگان به سایر نتایج جستجو نیز وابسته است.
اگر مشاهده کردید که بدون ایجاد تغییر در محتوا یا بکلینکهای سایتتان جایگاه شما در نتایج جستجو افت کرد بدانید که این اتفاق نتیجه رفتار کاربران است. آنها صفحاتی بهتر از صفحه شما پیدا کردهاند.
در ردهبندی نتایج جستجو، معیارهای تعاملی مانند یک عامل پشتیبان عمل میکنند. فاکتورهای هدف مانند لینک و محتوا باعث میشوند شما به جایگاه اول دست پیدا کنید، سپس این معیارها به گوگل کمک میکنند تا شما را ارزیابی کند و اگر وضعیت نشان دهد که شما لیاقت آن جایگاه را دارید، در آن رتبه تثبیت خواهید شد.
تکامل نتایج جستجو
در زمانهای قدیم که موتورهای جستجو به خوبی و باتجربگی امروز نبودند، اصطلاح “10 لینک آبی” برای شرح ساختار صفحه نتایج جستجو ابداع شد. هرزمانی که کاربر جستجویی انجام میداد، گوگل در جواب صفحهای شامل 10 نتیجه ارگانیک، همگی با یک شکل و فرمت ظاهری، به او نمایش میداد.
در این صفحه نتایج، دستیابی به جایگاه اول در سئو مانند به دست آوردن جام مقدس بود. اما بعد اتفاق دیگری افتاد. گوگل شروع به اضافه کردن نتایج در فرمت و شکلهای متفاوتی به صفحه نتایج جستجو کرد و اسم آنها را SERP features گذاشت. برخی از این امکانات جدید که به صفحه نتایج جستجو اضافه شدند شامل موارد زیر هستند:
- تبلیغاتهای پولی
- Featured snippets
- باکسهای People Also Ask (بقیه افراد جستجو کردهاند)
- Local Pack (بستههای مکانی که شامل نقشه و مکانهای منتخب بودند)
- Knowledge Panel (پنل دانش و اطلاعات)
- لینک سایتها
و بسیاری انواع جدید دیگر که گوگل در حال اضافه کردن آنها است. آنها حتی صفحه نتایج صفر (zero-result SERP) را نیز امتحان کردند. صفحهای که تنها یک نتیجه از Knowledge Graph (نمودار دانش) نمایش داده شده و کاربر برای مشاهده نتایج بیشتر باید بر روی گزینه View more results کلیک کند.
اضافه کردن این امکانات و ویژگیها در همان ابتدا نگرانی همه برانگیخت. این بانگیختگی دو دلیل مهم داشت. اول اینکه بسیاری از این امکانات باعث میشدند تا نتایج ارگانیک در جایی پایینتر از مکان قبلی خود در صفحه قرار بگیرند و دوم، به عنوان یک نتیجه جانبی باعث میشد که کاربران کمتر بر روی نتایج ارگانیک کلیک کنند زیرا بسیاری از جستارها در همان صفحه نتایج جستجو پاسخ داده میشدند.
پس چرا گوگل دست به چنین کاری زد؟ دلیلش به تجربه جستجو باز میگردد. رفتار کاربران نشان داده است که شکلهای دیگر محتوا به برخی از جستارها بهتر پاسخ میدهند. در ادامه توجه شما را به تطابق این امکانات با انواع جستارها جلب میکنیم.
| شکل و فرمت ظاهری محتمل محتوای نمایش داده شده در نتایج جستجو | نوع جستار یا هدف از جستجو |
| Featured snnipet | اطلاعاتی (informational) |
گراف دانش یا جواب مستقیم (Knowledge Graph/instant answer) | اطلاعاتی به همراه یک جواب (informational with one answer) |
| نقشه (Map Pack) | مکانی، محلی یا بومی (local) |
| فروشگاه یا خرید (Shopping) | معاملاتی (Transactional) |
درباره هدف جستجو در بخش سوم بیشتر صحبت خواهیم کرد. درحال حاضر چیزی که باید بدانید این است پاسخها میتواند به اشکال مختلفی به دست جستجوکنندگان برسد و اینکه ساختار محتوای شما به چه شکلی باشد، تاثیر بسزایی در فرمت ظاهری آن در نتایج جستجو خواهد داشت.
جستجوی مبتنی بر مکان (Localized search)
موتور جستجویی مانند گوگل فهرست مخصوصی از کسبوکارها و اطلاعات و مکان آنها در اختیار دارد که در نتایج جستجوی محلی از آنها استفاده میکند.
اگر شما به عنوان متخصص سئو برای کسب و کاری کار میکنید که یک مکان فیزیکی برای ارائه خدمت به مشتری دارد (مانند دندانپزشک) یا کسب و کاری که مکان ثابت ندارد و کارگر به مشتری مراجعه کرده و سرویس ارائه میدهد (مانند لولهکش)، مطمئن شوید که لیست کسب و کار گوگل خود را (Google My Business Listing) راهاندازی و بهینهسازی کردهاید.
هنگامی که نوبت به جستجوی مبتنی بر مکان میرسد، گوگل از سه فاکتور مهم برای ردهبندی نتایج استفاده میکند:
- ارتباط
- فاصله
- شهرت و اعتبار
ارتباط
ارتباط میزان تطابق کسب و کار محلی با چیزی است که کاربر به دنبال آن میگردد. برای اینکه مطمئن شوید کسب و کار شما به درستی با جستجوی کاربران مرتبط میشود، تمامی اطلاعات ضروری و مهم خود را با دقت در لیستهای کسب و کار وارد کنید و آنها را چک نمایید.
فاصله
گوگل از مکان جغرافیایی شما استفاده میکند تا خدمات مکانی بهتری به شما ارائه کند. نتایج جستجویهای محلی و مکانی به شدت نسبت به نزدیکی حساس هستند، نزدیکی نتیجه نمایش داده شده به مکان کاربر یا مکان ذکر شده در جستار. (اگر کاربر مکانی ذکر کرده باشد)
نتایج ارگانیک جستجو نیز نسبت به مکان کاربر حساس هستند، هرچند این حساسیت به اندازه جستارهای محلی و مکانی نیست.
شهرت و اعتبار
با درنظر گرفتن شهرت و اعتبار به عنوان فاکتوری برای ردهبندی، گوگل به دنبال این هدف است که به کسب و کارهای شناخته شده در دنیای واقعی یک امتیاز مثبت بدهد. علاوه بر شهرت و اعتبار آفلاین (خارج از اینترنت) یک کسب و کار، گوگل از برخی فاکتورهای آنلاین نیز برای تعیین ردهبندی کسب و کارها کمک میگیرد:
نظرات (Reviews)
تعداد نظراتی که کسب و کارهای موجود در گوگل دریافت میکنند و میزان رضایت آنها، تاثیر قابل توجهی بر جایگاه آن کسب و کار در ردهبندی نتایج جستجو دارد.
ارجاعات (Citations)
ارجاع به یک کسب و کار که تحت عناوین “business citation” یا “business listing” شناخته میشود، ارجاعی است که در بستر وب از سمت پلتفرمهای مبتنی بر مکانیابی (مانند اپلیکیشنهای مکانیاب از جمله نشان، گوگل مپ و ویز یا اپلیکیشنهای رستوران یاب مانند فیدیلیو و فوراسکوئر) به کسبوکار مذکور داده شود. این ارجاع شامل ذکر نام، آدرس، شماره تلفن و یک لینک از آن کسب و کار در بستر پلتفرم است.
تعداد و ارزش این ارجاعات تاثیر بسیاری بر ردهبندی نتایج مکانی دارد. گوگل این اطلاعات را از منابع مختلفی در سرتاسر دنیای وب جمعآوری کرده و به صورت مداوم از آنها برای بهبود نتایج جستجو استفاده میکند.
هنگامی که گوگل منابع محکمی بر نام، مکان، آدرس و شماره تلفن یک کسب و کار پیدا میکند اعتماد او نسبت به شهرت و اعتبار آن کسب و کار افزایش پیدا میکند. این نتایج منجر به نمایش کسب و کارهای با اعتبار بالا میشوند. گوگل همچنین از منابع دیگر موجود در سرتاسر وب، مانند لینکها و مقالات، نیز استفاده میکند.
ردهبندی ارگانیک
روشهای معمولی سئو برای سئو محلی نیز کاربرد دارند زیرا گوگل جایگاه وبسایت مربوط به کسب و کار در نتایج ارگانیک جستجو را در ردهبندیهای مکانی تاثیر میدهد.
در قسمت بعدی، شما با بهترین روشهای سئو داخلی آشنا خواهید شد تا بتوانید به کاربران و موتورهای جستجو کمک کنید تا محتوای شما را بهتر درک کنند.
تعاملات مکانی (local engagement)
اگرچه این فاکتور به عنوان یک فاکتور تاثیرگذار در ردهبندیهای مکانی ذکر نشد، اما نقش تعاملات مکانی در ردهبندی نتایج جستجو روز به روز بیشتر میشود. گوگل سعی دارد تا با استفاده از اطلاعاتی که از دنیای واقعی کسب میکند، مانند زمانهای مناسب برای بازدید یک مکان یا میانگین طول بازدید و غیره، نتایج جستجو را غنیتر نماید.
همچنین این امکان نیز فراهم شده است که کاربران بتوانند سوالات خود را در رابطه با کسب و کارها مطرح نمایند.
به همین دلیل بدون شک امروزه بیش از هر زمان دیگری نتایج مکانی از دادههای دنیای واقعی تاثیر میپذیرند. به جای استفاده از اطلاعات کاملا ایستا و قابل دستکاری مانند لینکها و ارجاعات، این روش، روش جدیدی برای ارزیابی تعامل و علاقه کاربران به کسب و کارها است.
به دلیل اینکه هدف گوگل ارائه بهترین و مرتبطترین نتایج مکانی به جستجوهای کاربران میباشد، استفاده از معیارهای تعاملی واقعی و همزمان، برای سنجش کیفیت و ارتباط از طرف خود کاربران بهترین راهحل به نظر میرسد.
شما نیاز ندارید که زیر و بم تمام الگوریتمهای گوگل را بیاموزید (چیزی که هیچکس نمیداند و همیشه به عنوان یک راز باقی خواهد ماند)، اما تاکنون و با استفاده از این مطالب دانش پایهای به دست آوردید که بتوانید فرآیند جستجو، یافتن، بررسی، ذخیره و ردهبندی محتواهای مختلف توسط موتورهای جستجو را درک کنید.
با داشتن این دانش، در قسمت بعدی انتخاب کلیدواژههای هدف برای تولید یک محتوای مناسب را خواهید آموخت.