


راهنمایی عملی برای گروهبندی سریعتر و دقیقتر کلمات کلیدی با استفاده از مقایسه SERP و زبان پایتون
نیت جستوجو (Search Intent) موضوعی پیچیده است. از استفاده از یادگیری عمیق برای طبقهبندی متون گرفته تا تجزیهوتحلیل عنوانهای نتایج گوگل با NLP، و خوشهبندی بر اساس ارتباط معنایی — همگی روشهایی هستند که مزایای آنها نیز روشن است.
ما هم میدانیم درک نیت جستوجو چه مزایایی دارد، و هم ابزارهایی در اختیار داریم که این کار را در مقیاس بالا و بهشکل خودکار انجام دهند.
اما چرا یک مقالهٔ دیگر دربارهٔ خودکارسازی نیت جستوجو لازم است؟
زیرا با ورود فناوری جستوجوی مبتنی بر هوش مصنوعی، درک نیت جستوجو اهمیت بسیار بیشتری یافته است.
در دوران “۱۰ لینک آبی” شاید امکان نمایش گزینههای بیشتر وجود داشت. اما موتورهای جستوجوی هوش مصنوعی به دلیل بهینهسازی هزینههای پردازشی (FLOP)، تمایل دارند فقط نتایج دقیق و مناسب را نمایش دهند.
چرا هنوز SERP بهترین شاخص برای نیت جستوجو است؟
در اکثر روشها شما باید خودتان مدل AI بسازید: یعنی عنوانهای صفحات نتایج را استخراج کرده، آنها را به مدل شبکه عصبی بدهید و آموزش دهید. یا با NLP خوشهبندی انجام دهید.
اما اگر زمان یا دانش ساخت این مدلها را نداشته باشید چه؟
خدمات سئو سایت به صورت 0 تا 100 به همراه طراحی UI/UX، طراحی سایت وردپرسی، تواید محتوا، پشتیبانی فنی، ادمین، وب اپ، تصویر برداری، فیلم برداری، استراتژی کسب و کا و … ارائه می شود.
بسیاری به شباهت کسینوسی (Cosine Similarity) بهعنوان روش خوشهبندی کلمات کلیدی تکیه میکنند، اما به نظر من، مقایسه نتایج SERP برای کلمات مختلف همچنان روش برتری است.
چرا؟ چون مدلهای AI نیز رفتارشان را بر پایه SERP طراحی میکنند — یعنی دقیقاً آنچه کاربر میبیند.
و حالا راهی وجود دارد که از خود گوگل برای انجام این کار استفاده کنیم، بدون اینکه نیاز به استخراج محتوا یا ساخت مدل هوش مصنوعی باشد.
فرض کنیم ترتیب نمایش URLها در نتایج گوگل، احتمال رضایت کاربران از هر نتیجه را نشان میدهد. در این صورت اگر نیت جستوجو برای دو کلمه یکی باشد، SERP آنها هم باید شبیه باشد.
این ایده جدید نیست — سئوکاران حرفهای سالهاست برای شناسایی نیت جستوجو از مقایسه SERP استفاده میکنند.
نوآوری این مقاله در خودکارسازی و مقیاسپذیری این مقایسههاست: سرعت بیشتر، دقت بالاتر.
آموزش گامبهگام خوشهبندی کلمات کلیدی بر اساس نیت جستوجو با پایتون
مرحله ۱: وارد کردن فایل SERP به پایتون
import pandas as pd
import numpy as np
serps_input = pd.read_csv(‘data/sej_serps_input.csv’)
del serps_input[‘Unnamed: 0’]
مرحله ۲: فیلتر نتایج صفحه اول گوگل
serps_grpby_keyword = serps_input.groupby(“keyword”)
k_urls = 15
def filter_k_urls(group_df):
return group_df[(group_df[‘url’].notnull()) & (group_df[‘rank’] <= k_urls)]
filtered_serps = serps_grpby_keyword.apply(filter_k_urls)
filtered_serps_df = filtered_serps.reset_index(drop=True)
طراحی سایت وردپرسی به صورت حرفه ای به همراه هاست، طراحی گرافیکی، زیرساخت سئو، پلاگین های اختصاصی و پشتیبانی فنی انجام می شود.
مرحله ۳: فشردهسازی URLهای هر کلمه در یک رشته
filtserps_grpby_keyword = filtered_serps_df.groupby(“keyword”)
def string_serps(df):
df[‘serp_string’] = ”.join(df[‘url’])
return df
strung_serps = filtserps_grpby_keyword.apply(string_serps)
strung_serps = strung_serps[[‘keyword’, ‘serp_string’]].drop_duplicates()
مرحله ۴: ساخت ترکیبهای دوتایی برای مقایسه SERP
def serps_align(k, df):
…
matched_serps = pd.DataFrame(columns=[‘keyword’, ‘serp_string’, ‘keyword_b’, ‘serp_string_b’])
for q in strung_serps.keyword.to_list():
temp_df = serps_align(q, strung_serps)
matched_serps = matched_serps.append(temp_df)
مرحله ۵: تعریف تابع شباهت SERP
def serps_similarity(serps_str1, serps_str2, k=15):
…
return intent_dist
matched_serps[‘si_simi’] = matched_serps.apply(lambda x: serps_similarity(x.serp_string, x.serp_string_b), axis=1)
خوشهبندی کلمات کلیدی بر اساس نیت
آستانهٔ شباهت در اینجا ۰.۴ در نظر گرفته شده است.
با بررسی تشابهها، کلمات به گروههای موضوعی تخصیص داده میشوند.
خروجی نهایی: دیتافریمی با گروهبندی کلمات بر اساس نیت جستوجو
topic_groups_dictdf = pd.DataFrame(topic_groups_lst, columns=[‘topic_group_no’, ‘keyword’])
✔ طراحی سایت وردپرسی به صورت کاملا حرفه ای و در سطح جهانی در شرکت یاسئومی انجام می شود و پشتیبانی فنی 24 ساعته ارائه می شود. خدمات سئو ما طراحی سایت رایگان دارد.
کاربردهای عملی
بهبود معماری سایت
ساخت خوشههای محتوایی هدفمند
طراحی کمپینهای تبلیغاتی بر اساس intent
ایجاد ساختار داشبوردهای سئو دقیقتر
یکپارچهسازی URLهای بیکاربرد در سایت فروشگاهی
جمعبندی
این روش، راهی دقیق، سریع و مقیاسپذیر برای خوشهبندی کلمات کلیدی بر اساس نیت جستوجو است. بدون نیاز به مدلسازی پیچیده یا هزینه API، میتوانید با پایتون و دادههای SERP به نتایجی مشابه ابزارهای حرفهای برسید.







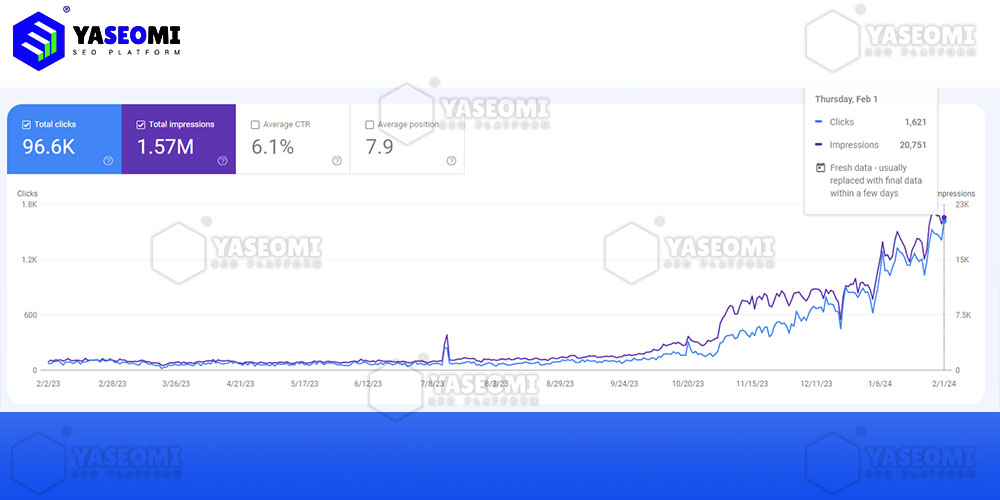{kind=link}
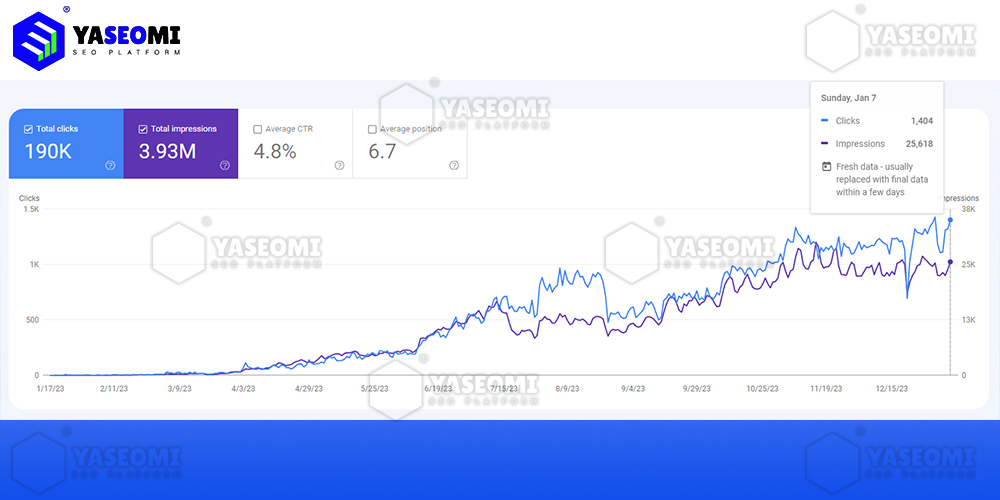{kind=link}
{kind=link}
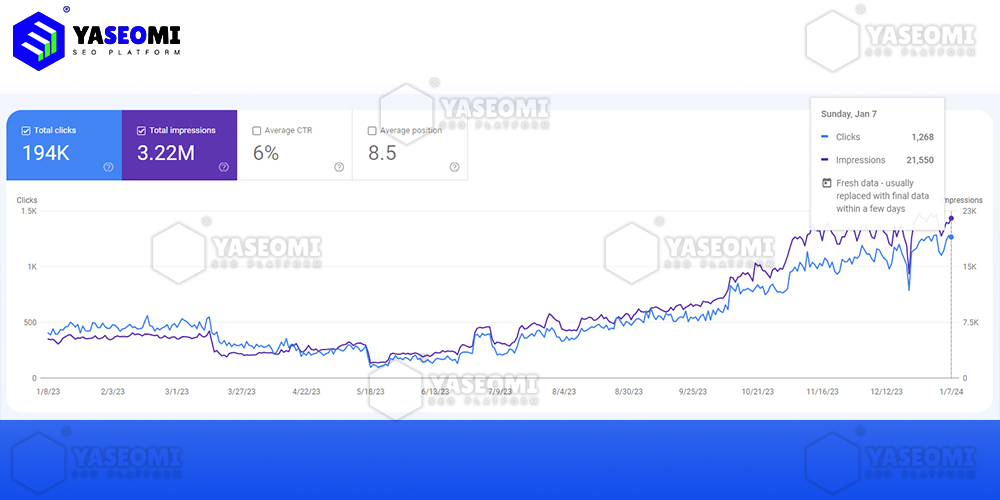{kind=link}